|
February 15, 2002
|
|
 |
 |
| VISTA gives a wide view of genomic comparisons | ||
| Contact: Paul Preuss, paul_preuss@lbl.gov | ||
|
|
Inna Dubchak of the National Energy Research
Scientific Computing Center (NERSC), located at Berkeley Lab, has specialized
in computer programs to make biological databases more useful. When her
colleagues in the Life Sciences Division's Genome Science Department asked
her to develop a database of noncoding regions in the genomes of human,
mouse, and other organisms, she realized there were no good tools for comparing
one genome with another in a simple, easy-to-read way. "So I set out
to make one."
Entering the Genomic Era Often regulatory sequences are only a few base-pairs long, much harder to find and easier to confuse than long, patterned gene sequences. One way to discover them in noncoding DNA (few call it "junk" anymore) is by searching conserved areas, sequences that have persisted for millions or hundreds of millions of years of evolution. Genome comparison is crucial to the process. If a given DNA sequence is substantially similar in both mouse and human, for example, that sequence has persisted since the common ancestor of mice and humans, some 80 to 100 million years. It is not surprising to find the same sequence conserved in monkeys, pigs, and rabbits; there may even be some comparison to more distant species like chickens or fugu fish. VISTA can compare sequences from two organisms or several, looking for similarities, or compare the DNA of closely related species, underlining their differences. The program can look for regulatory sequences as well as genes; it can analyze noncoding sequences for stretches that are actively conserved. All of these tools are available on the web, where biologists can use the VISTA server or download a stand-alone package.
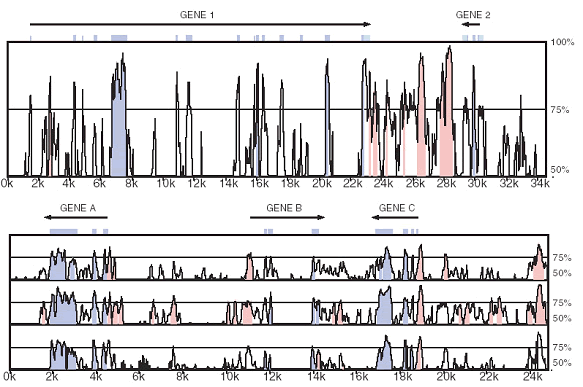
Making it easy on the user Next a sliding "window," its length (in base pairs) specified by the user, moves along the sequence of the first organism, counting the number of identical nucleotides in the comparison organism within the window centered at each base position and calculating the degree of identity between them. VISTA plots the nucleotide sequence of the first organism from right to left and vertically plots the percent identity of the organism to which it is being compared. The result is a visual series of little mountain peaks, sequences of specified length and a minimum degree of identity, their similarities obvious at a glance. If the sequence of the first organism has been annotated -- noting where genes begin and end and where other known features reside -- what these features have in common with the comparison organism are visible at a glance. When comparing two closely related species like human and chimpanzee, biologists are more interested in differences than in similarities. Not long ago, chimpanzees were considered so genetically similar to humans that it was hard to understand how our physical differences had arisen. VISTA graphically points up the differences among genes and other DNA sequences common to humans and nonhuman primates, giving hints of their evolutionary origins. VISTA has also been used extensively to compare the conserved regions in the whole genomes of the human and mouse, finding regions at any level of conservation the user defines. Every human chromosome contains regions with a high degree of mouse-human similarity. Although noncoding regions in two species could be similar by accident, similarity in three or more species means they have been conserved in evolution. By comparing sequences from at least three organisms -- human, mouse, and dog, for example -- conserved noncoding sequences are quickly identified. Tracking down potential regulatory sequences within noncoding regions uses a "flavor" of VISTA that draws upon other existing databases to hone in on likely gene-regulation sites. In them, any short regions (20 base pairs) with greater than 80 percent identity are swiftly identified. A panoramic VISTA By sifting valuable "ore" out of the increasing amounts of sequence that is emerging from genome-sequencing institutions around the world, VISTA is one of the tools that's helping the Genomic Era deliver on its promises. Since the VISTA server went online in mid-2000, nearly 6,000 queries have been handled, coming from over 600 users in 26 countries. Three hundred and twenty copies of the stand-alone program have been distributed. To build VISTA, Dubchak worked with biologists and computer scientists
both: biologist Edward Rubin, with Poulabi Bannerjee, Dario Boffelli,
Kelly Frazer, Gabriela Loots, and Len Pennacchio; mathematician Lior Pachter;
and computer scientists and programmers Alexander Poliakov, Jody Schwartz,
Chris Mayor, Michael Brudno, Ivan Ovcharenko, and Nicolas Bray. Additional information:
|
||||||||||||||||||||